Introduction au cluster sous Linux

Ce tutoriel fait suite à celui sur la mise en place de RAID. Après avoir apporté de la redondance et de la tolérance de panne aux disques contenant les données il est également important voir crucial de faire la même chose pour les serveurs.
I. Introduction sur les clusters
I.1. Qu’est-ce qu’un cluster ?
Littéralement un cluster est une « grappe », en informatique on parlera donc de grappe d’ordinateurs comme on peut aussi parler de grappe de disques durs pour le RAID. Disposer d’un cluster revient à disposer de plusieurs serveurs formant une seule entité. Il existe deux types d’utilisations pour les clusters :
- Le calcul distribué, ici on utilise la puissance de calcul de toutes les machines du cluster afin de réaliser de grandes opérations arithmétiques. Ils sont souvent utilisés dans les laboratoires de recherches ou les calculs météorologiques.
- La haute disponibilité des infrastructures notamment dans l’utilisation du load-balancing (répartition de charge entre serveurs). Cela à pour but de favoriser la continuité de service. Dans ce cadre là toutes les machines physiques ne forment qu’une machine logique et le gestionnaire de cluster gère le failover (basculement) en cas de panne d’un noeud.
I.2. Présentation des outils utilisés
Pacemaker est un gestionnaire de cluster. Il est garant de la haute disponibilité des nœuds de votre cluster en détectant et réparant les erreurs entre les nodes. Celui-ci utilise la couche de message fournit par corosync ou heartbeat.
Fonctionnalités principales de pacemaker :
- Détecter et réparer les erreurs entre les nodes du cluster
- Compatible STONITH, garantie l’intégrité de vos données
- Autant à l’aise sur les petits que les grands clusters
- Réplique automatiquement sa configuration sur les autres nodes du cluster lorsqu’un noeud est paramétré
- Gestion du stockage et des ressources cluster
- Support de toutes les architectures redondantes
###I.2.1. Les types de cluster supportés
- Cluster Actif/Passif
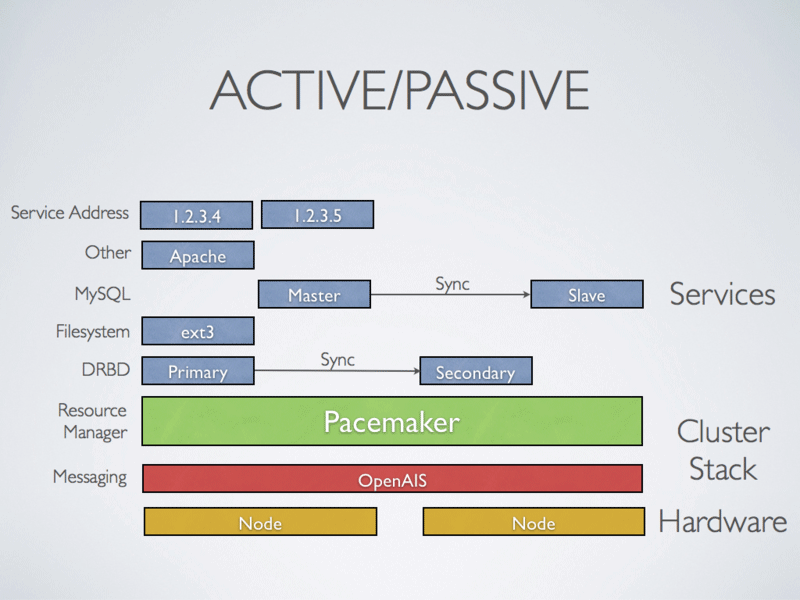
Dans cette configuration, il y a une véritable notion de maître / esclave entre les noeuds du cluster. Couplé à DRBD (système de RAID Over IP, prochaine article), celui-ci offre une topologie haute disponibilité très satisfaisante. En mode actif/passif, un noeud est désigné maître, il gère la ressource partagé, son contenu est monté, la réplication est effectuée au niveau des blocks sur l’autre noeud. Si le noeud maître tombe, le second noeud prend le relais de la ressource et monte le device. Les données sont toujours présentes et on peut continuer à écrire de façon transparente. Lorsque la machine anciennement maître du cluster sera de nouveau opérationnelle, elle sera désignée comme esclave. Voilà comment s’effectuent les bascules.
- Cluster N+1
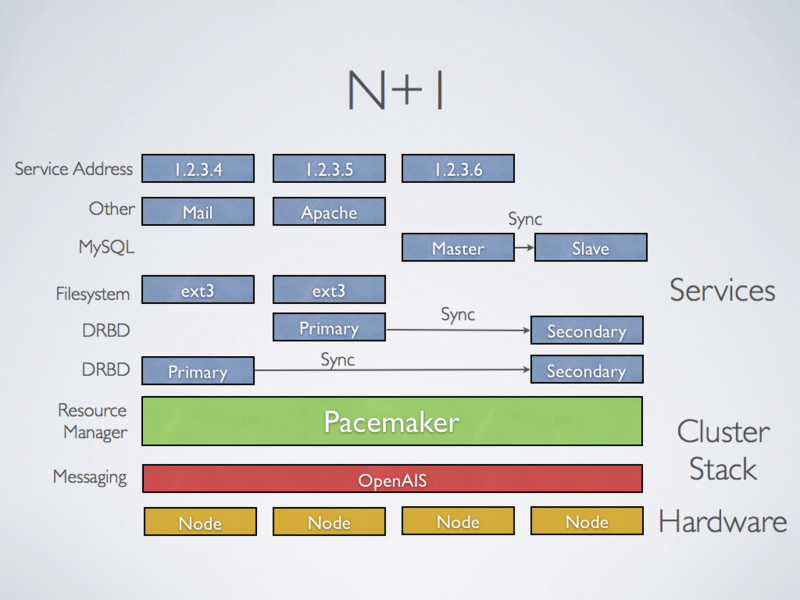
Dans cette configuration, on combine plusieurs machines en mode actif/passif afin d’augmenter la disponibilité. Même principe que la première topologie mais à plus grande échelle.
- Cluster Actif/Actif ou N To N

Dans cette configuration, la basculement est complètement transparent. En effet, sur un cluster actif/passif on utilise un système de fichiers ne pouvant être monté qu’une seule fois, c’est le cas de ext2,ext3,ext4. Hors ici on utilise un système de fichier distribué comme GFS ou OCFS2. On écrit donc sur un disque et la donnée est instantanément répliquée sur les autres noeuds. De plus, pacemaker peut gérer plusieurs services afin d’alléger la charge de travail de chaque noeud.
Pour plus d’informations et de détails sur le projet je vous invite vivement à aller sur le site officiel
I.3. Pré-requis
Comme toujours pour mes tests j’ai utilisé des machines virtuelles, idéalement j’ai récupéré ma VM de test de RAID (on en aura besoin plus tard) :
- 2 VM Debian 6 Squeeze
- RAM : 192 Mo
- Core : 1
- 1 disque système 5 Go
- 2 disques pour le RAID 1 Go
- 2 cartes réseau :
- NAT : 192.168.101.160 – 192.168.101.161
- Private : 10.0.0.1 – 10.0.0.2
Je passe les étapes d’attributions d’adresses IP statiques. Avant de démarrer vérifier que les IP du réseau Private se ping bien. Voici mon fichier /etc/network/interface :
root@cluster-node-1:~# cat /etc/network/interfaces
# This file describes the network interfaces available on your system
# and how to activate them. For more information, see interfaces(5).
# The loopback network interface
auto lo
iface lo inet loopback
# The primary network interface
#allow-hotplug eth0
#iface eth0 inet dhcp
@auto eth0
iface eth0 inet static
address 192.168.101.157
netmask 255.255.255.0
gateway 192.168.101.2
# The second network interface
auto eth1
iface eth1 inet static
address 10.0.0.1
netmask 255.0.0.0
II. Mon premier cluster
II.1. Installation et configuration de corosync
Corosync est un outils permettant d’implémenter un cluster de type tolérance de panne. Dans le principe on a 2 serveurs (ou plus) reliés à la fois au réseau local et par une connexion privé, les 2 serveurs ne forment qu’une seule machine mais seul un des deux fournit le service. C’est corosync qui gère le basculement grâce à la ligne de vie (lien entre les machines du cluster) lorsqu’un serveur tombe, l’autre noeud prend le relais. Celui-ci fait parti des dépendances du paquet pacemaker.
Dans un premier temps nous allons installer le paquet necessaire :
root@cluster-node-1:~# aptitude install -y pacemaker |
Générer la clef d’authentification entre chaque node :
root@cluster-node-1:~# corosync-keygen |
La clef sera générée dans /etc/corosync/authkey, cette clef doit être copiée sur chaque node du cluster. Pour copier sur le node 2 on utilise SCP :
root@cluster-node-1:~# scp /etc/corosync/authkey root@cluster-node-2:/etc/corosync/ |
Maintenant il faut éditer le fichier /etc/corosync/corosync.conf pour renseigner le réseau ou sous-réseau des clusters, dans notre cas c’est 10.0.0.0 :
interface {
# The following values need to be set based on your environment
ringnumber: 0
bindnetaddr: 10.0.0.0
mcastaddr: 226.94.1.1
mcastport: 5405
Activer le service (seulement valable pour Debian et Ubuntu), éditer /etc/default/corosync and mettre START=yes.
Démarrer le daemon corosync :
root@cluster-node-1:~# /etc/init.d/corosync start |
À ce stade on peut déjà remarquer que les noeuds sont bien connectés entre eux mais que le cluster n’est pas encore entièrement configuré. Vérifions cela avec la commande :
root@cluster-node-1:~# crm_mon --one-shot -V |
On observe que les noeuds sont bien connectés. À noter que la commande crm_mon -1 fait la même chose.
II.2. Paramétrage du cluster
Maintenant nous allons attribuer une adresse IP virtuelle au cluster, pour cela nous allons utiliser la cli CRM (Cluster Resource Manager) :
root@cluster-node-1:~# crm |
On désactive l’exemple STONITH, pour faire simple c’est une fonction de sécurité des données lors du basculement. Il est garant de l’intégrité des données à chaque bascule. Ici nous n’en avons pas besoin.
crm(ma-config-cluster) |
Et enfin on assigne une adresse IP virtuelle au cluster et on gère la bascule entre les noeuds :
crm(ma-config-cluster)configure# primitive failover-ip ocf:heartbeat:IPaddr params ip=10.0.0.100 op monitor interval=10s |
Descriptions des arguments :
primitive, argument pour ajouter une primitive. Mais une primitive c’est quoi ? Un paramètre renseignant plusieurs valeurs indiquant au cluster quels scripts utiliser pour la resource, où le trouver et à quel standard il correspond.failover-ipest le nom de la primitiveocf, classe de la resourcehearbeat, provider de la resourceIPaddr, RA (Resource Agent) gérant les adresses IPv4 virtuellesparams, déclaration des paramètresip=10.0.0.100, IP du failoverop, les options- monitor`, action à effectuer, ici le monitoring de la ligne de vie
interval=10s, on définit l’interval auquel on effectue l’action de monitoring.
On vérifie et valide les commandes :
crm(ma-config-cluster)configure# verify |
Et voilà ! Le cluster est activé et fonctionnel !
root@cluster-node-1:~# crm_mon --one-shot -V |
Quoi c’est tout ? Et oui vraiment, légère déception comme pour le RAID. Vous pouvez maintenant faire des tests de basculements simplement en éteignant un des deux nodes, normalement les ressources devraient basculer sur le node restant. Vous pouvez vérifier cela avec la commande
crm_mon --one-shot -V
la variable Started devrait changer.
III. Tricks and tips
III.1. Changer l’IP virtuelle du cluster
Petite astuce pour changer l’IP du cluster :
root@cluster-node-1:~# crm |
Après avoir rentré la commande « edit » vous pourrez éditer la configuration du fichier du cluster, chercher la ligne correspondante à l’adresse IP virtuelle du cluster et renseigner la nouvelle IP. Après avoir commiter faîte un petit test de ping pour voir que tout fonctionne et que la ressource est maintenant accessible sur la nouvelle adresse.
III.2. Changer l’éditeur de fichier par défaut
Voici comment changer l’éditeur de configuration par défaut, ici on ajoute l’éditeur nano :
root@cluster-node-1:~# crm |
III.3. Ajouter un noeud au cluster
Rien de plus simple, il suffit simplement d’appliquer le même paramétrage qu’aux deux nodes précédent. En résumé :
- Installer pacemaker
- Via SCP on copie le fichier /etc/corosync/corosync.conf sur le nouveau node
- Toujours via SCP on copie la authkey sur le nouveau node.
- Lancer le daemon corosync avec la commande /etc/init.d/corosync start
III.4. Mettre des nodes en standby
Pour des raisons de maintenances, mise à jour ou autre on peut avoir besoin de mettre en standby un node du cluster, pour cela :
root@cluster-node-1:~# crm |
Vous devriez observer le basculement de la ressource sur l’autre noeud du cluster. Pour remettre celui-ci en ligne :
root@cluster-node-1:~# crm |
III.5. Migrer le node maître volontairement
Après la manipulation précédente la ressource du cluster est sur le node 2 si vous avez mis en standby le node 1 ou inversement. Vous voulez peut être que le node 1 (ou 2) reprenne le contrôle de la ressource, pour cela :
root@cluster-node-1:~# crm |
III.6. Arrêter et supprimer une ressource du cluster
Vous vous êtes trompé et voulez recommencer ?
root@cluster-node-1:~# crm resource stop ma_resource |
III.7. Voir sur quel node fonctionne la ressource
Rentrer la commande suivante :
root@cluster-node-1:~# crm_resource -r failover-ip -W |
III.8. En savoir plus sur les ressources OCF
Concernant les primitives, il y en a plusieurs que l’on peut configurer (nous verrons ça plus précisément dans le prochain article). On peut déjà se faire une idée avec la commande suivante :
root@cluster-node-1:~# crm ra list ocf heartbeat |
Ici on a listé les resources disponibles pour heartbeat mais on peut également le faire pour pacemaker.
Pour plus de détails sur chaque resource, leurs paramètres et leur syntaxe :
root@cluster-node-1:~ |
Tout comme pour l’article sur les clusters, l’essentiel est là après à vous de fouiller la console crm.
Bon cluster !
Comments