RAID Over IP en mode Actif/Passif sur un failover cluster

Suite des tutos sur le haute disponibilité. Après avoir configuré des disques en RAID, mis 2 serveurs en cluster avec gestion du failover nous allons maintenant mettre en place du RAID 1 Over IP afin de disposer des mêmes données sur les disques de chaque serveurs membres du cluster. La topologie proposée est basée sur du RAID 0 sur les serveurs. Ici on passe aux choses sérieuses mais ne vous en faites pas vous êtes déjà des As du cluster !
I. Introduction au RAID Over IP
I.1. C’est quoi ?
Vous vous souvenez du RAID 1 ? Et bien c’est la même chose mais à travers le réseau. Le contenu de chaque disque est répliqué instantanément sur l’autre. Bien évidemment les machines seront connectées entre elles via une liaison spéciale 1Gb afin de maximiser les échanges et les taux de transferts. Ce n’est rien de plus et rien de moins . Cette technique a l’avantage de proposer plusieurs points de stockage des données (à l’instar d’un SAN), il n’y a donc aucun SPOF. Les noeuds peuvent tomber et être basculés (failover) et remontés (failback) sans conflit d’écritures car la ressource est toujours gérée par un seul noeud.
I.2. Présentation de l’ outil utilisé
Le RAID Over IP introduit un nouveau projet dans notre architecture : DRBD pour Distributed Replicated Block Device en anglais, ou périphérique en mode bloc répliqué et distribué en français. Celui-ci gère la synchronisation des données par blocks entre chaque périphérique block de chaque noeud d’un cluster. Les données sont répliquées à la volée à chaque fois que celles-ci sont écrites. Point qui a tout de même son importance DRBD n’est pas capable de gérer plus de 2 nodes mais si l’on en croit la roadmap du projet la version 9 devrait pouvoir en gérer plus. Voici un schéma du fonctionnement :
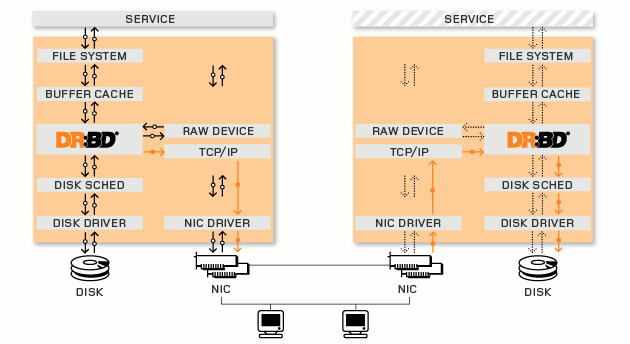
Liste des principales fonctionnalités :
- Apporte de la redondance de données au sein d’un cluster
- Permet l’authentification entre les noeuds
- Gestion des crashs avec système de recovery/reconstruction des données entre nodes
- Support des architectures active/passive et active/active (avec système de fichiers distribués)
- Compatible LVM, hearbeat, Corosync, Pacemaker
Pour plus d’informations et de détails sur les fonctionnalités de DRBD, je vous invite à aller sur le site officiel
I.3. Pré-requis
Comme pour mes tests précédents j’ai réutilisé le failover cluster existant et ses disques en RAID 0. La configuration est donc la suivante :
- 2 VM Debian 6 Squeeze
- 1 core
- 192 Mo de RAM
- 3 disques
- 1 disque système 5 Go
- 2x 1Go de disques de données en RAID 0
- 2 cartes réseaux
- Publique : 192.168.101.160 – 192.168.101.161
- Privé : 10.0.0.1 – 10.0.0.2
- Paquets nécessaires : dbadm drbd8-utils pacemaker
II. Mise en place
La topologie proposée est la suivante :
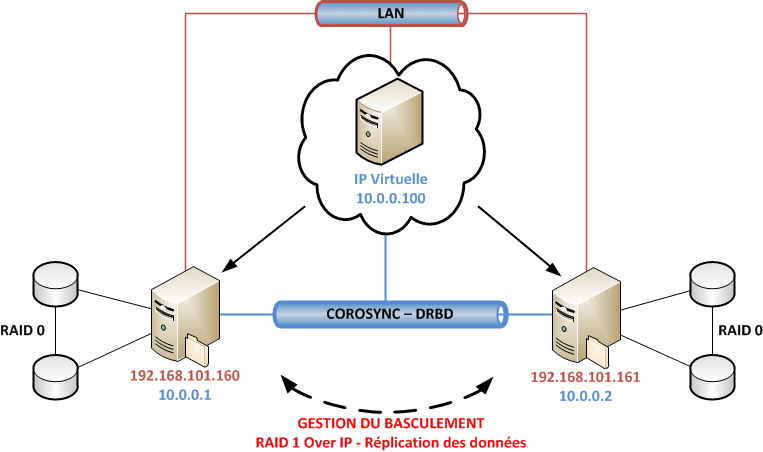
Nos précédentes implémentations de cluster ne géraient que le failover (le basculement) ce qui en soit ne sert à rien si le cluster ne fournit aucun service. À des fins de tests c’est intéressant afin de comprendre la configuration des primitives mais concrètement personne n’utilise uniquement le failover entre deux serveurs. Dans cette topologie nous allons rajouter du service, ici un service de backup de données mais on peut également gérer cela comme du partage réseau en montant des lecteurs pour les utilisateurs. Les utilisateurs possèdent des lecteurs réseaux paramétrés avec l’IP virtuelle du cluster et le répertoire de partage. C’est complètement transparent.
On allie donc :
- Forte disponibilité (failover)
- Redondance (RAID Over IP)
- Performance (RAID 0)
II.1. Configuration de DRBD
Avant de débuter les détails d’installations et de configurations voici quelques conventions de nommage :
root@cluster-node désigne les 2 nodes, la configuration doit se faire sur les deux nodes
root@cluster-node-1 : la configuration se fait sur le node 1
root@cluster-node-2 : la configuration se fait sur le node 2
Tout d’abord installer le paquet DRBD sur les 2 nodes :
root@cluster-node:~# aptitude install drbd8-utils |
L’essentiel des configurations s’effectue dans /etc/drbd.d/.
Maintenant on active le module drbd sur le noyau :
root@cluster-node:~# modprobe drbd |
Jetons un oeil aux fichiers de configurations disponibles :
/etc/drbd.conf, contient des includes du répertoire et fichiers ci-dessous./etc/drbd.d/global_common.conf, contient la configuration globale de drbd./etc/drbd.d/*.res, contient les fichiers de configuration des resources du cluster.
###II.1.1. Configuration de global_common.conf
Personnellement je n’ai pas fouillé beaucoup les options disponibles mais j’en ai retenu une particulièrement indispensable, pour le reste je vous laisse au bon vieux man. On remarquera que ce fichier est organisé par section, ici nous allons nous intéresser à la section « common » puis « syncer » afin de modifier la vitesse de transfert lors de la synchronisation des blocks. En effet, par défaut celle-ci est à 250 Kb/sec ce qui est extrêmement lent. Ainsi on va rajouter un nouvelle valeur pour outrepasser celle par défaut :
rate 40M; |
###II.1.2. Configuration de la resoure
Nous allons créer un fichier de resource dans /etc/drbd.d/ avec l’extension .res . Le nom n’est pas spécialement important personnellement je l’ai appelé r-data.
root@cluster-node:~# vim /etc/drbd.d/r-data.res |
Voici mon fichier de configuration (scrupuleusement identique sur les 2 noeuds) :
resource r-data { |
Une fois cette configuration identique sur les 2 noeuds on peut débuter la synchronisation. Avant de commencer il faut savoir que les données présentent sur les disques à synchroniser seront effacées, je suis donc pas responsable en cas de perte de vos données, vous savez et êtes conscient de ce que vous faîtes. Vous êtes prévenus . On écrase tout file system comme cela :
root@cluster-node:~# dd if=/dev/zero of=/dev/md0 bs=1M count=128 |
Puis sur les deux nodes :
root@cluster-node:~# drbdadm create-md r-data |
Ensuite on attache et on connecte la resource : (contraction des commandes attach et connect par la commande up)
root@cluster-node:~# drbdadm up r-data |
Enfin sur un seul node :
root@cluster-node-1:~# drbdadm -- --overwrite-data-of-peer primary r-data |
La synchronisation a débuté, on peut voir son avancement en faisant :
root@cluster-node:~# cat /proc/drbd |
En exécutant plusieurs cat avec une commande watch (sur un interval de 2 sec par exemple) on peut voir l’avancement, néanmoins si comme moi vous ne saviez pas lorsque vous avez commencé votre synchronisation que la vitesse de transfert était plafonnée à 250Kb/sec vous pouvez rectifier le tire « à chaud » durant le transfert. Il faut pour cela modifier le fichier de configuration général dans /etc/drbd.d/global_common.conf et ensuite lancer la commande :
root@cluster-node-1:~# drbdadm adjust all |
Comment ça je fais cela sur un seul node ? Oui une fois connecté la configuration est automatiquement répliquée entre les noeuds , si c’est pas beau ça . Le changement sera immédiat et vous verrez la vitesse de transfert progressivement augmenter jusqu’au taux indiqué.
Une fois terminé on va simplement créer le file system, pour rappel ici nous sommes en mode actif/passif nous n’avons donc pas besoin de système de fichiers distribué, ainsi ext2,ext3 ou ext4 feront très bien l’affaire.
root@cluster-node-1:~# mkfs.ext3 /dev/drbd0 |
On monte le disque :
root@cluster-node-1:~# mount /dev/drbd0 /mnt/drbd |
Voyons maintenant le status du disque :
|
Celui-ci fonctionne bien . Actuellement il n’y a aucune gestion de basculement automatique. Mais quelque test simple peuvent être réalisés afin de vérifier le bon fonctionnement de drbd, en commençant par créer un fichier sur le disque :
root@cluster-node-1:~# > /mnt/drbd/node1 |
On démonte ensuite la partition sur le serveur primaire :
root@cluster-node-1:~# umount /mnt/drbd |
On passe le serveur primaire en serveur secondaire :
root@cluster-node-1:~# drbdadm secondary r-data |
On passe le serveur secondaire en serveur maître :
root@cluster-node-2:~# drbdadm primary r-data |
On monte le disque :
root@cluster-node-2:~# mount /dev/drbd0 /mnt/drbd |
Voilà ça fonctionne. On peut s’amuser à faire la manipulation dans l’autre sens afin que le node 1 reprenne la main.
Dans la partie qui suit nous allons voir comment automatiser le basculement après une panne. Typiquement si le node 1 tombe, le file system sera remonté automatiquement sur le node 2 et sans encombre.
###II.1.3. Gestion du basculement automatique
Nous allons paramétrer pacemaker donc réutiliser la CLI avec crm. On commence tout d’abord par créer une nouvelle CIB (Cluster Information Base) pour plus de clareté.
root@cluster-node-1:~# crm |
On configure la primitive :
crm(drbd)# configure primitive share-drbd ocf:linbit:drbd params drbd_resource=r-data op monitor interval=60s |
Détail des principales options :
- Nom de la primitive : share-drbd
ocf:linbit:drbd, on utilise la classe ocf avec le provider linbit et le RA drbd drbd_resource, resource à utiliser
On définit une resource master :
|
Détail des principales options :
ms: nom du master/slave Data
On applique la configuration au cluster :
|
Si on sort du CLI on peut vérifier le statut :
|
Nous allons maintenant créer une autre cib et configurer la gestion du file system sur le cluster :
|
Détail des paramètres :
primitive DataFS, nom de la primitiveocf:heartbeat:Filesystem, classe+provider+RA, ici on gère le file systemdevice= /dev/drbd0, le device qui héberge notre resourcefstype= ext3, le système de fichier de /dev/drbd0
On définie où se trouve le file system, ici sur le primary :
crm(fs)# configure colocation fs_on_drbd : DataFS Data:Master |
Détail des paramètres :
colocation, on gère la relation entre les resources fs_on_drbd,inf: DataFS, valeur définissant que la resource doit être lancée sur le même node que la resource qui suit
On indique également sur quel noeud celui-ci doit se lancer :
crm(fs)# configure order DataFS-after- inf: :promote DataFS:start |
Détail des paramètres :
order, on gère plusieurs resource et on les ordonneDataFS-after-Data, on lance DataFS après la resourceData
Maintenant on applique les changements :
crm(fs)# cib commit fs |
Avec un crm_mon on voit que la resource est active :
root@cluster-node-1:~# crm_mon |
Est-ce que ça fonctionne ? OUI !
III. Test de fonctionnement
Pour vérifier si le basculement automatique est bien géré il suffit de simuler une panne comme nous l’avons fait dans l’article d’introduction aux clusters. Tout d’abord voici l’état de fonctionnement du cluster avec crm_mon :
root@cluster-node-1:~# crm_mon |
Ensuite rendez-vous dans la CLI de crm et mettre le node 1 en standby :
root@cluster-node-1:~# crm |
Le changement devrait être instantané, d’ailleurs si vous êtes en train de monitorer avec un crm_mon sur l’autre noeud vous devriez voir :
root@cluster-node-2:~# crm_mon |
Et observer également que le disque est bien monté :
root@cluster-node-2:~# drbd-overview |
Maintenant vous pouvez faire remonter votre node 1 comme suit :
root@cluster-node-1:~# crm |
Encore une fois la bascule est automatique et c’est le cluster-node-1 qui redevient maître de la resource !
Voilà le tutoriel touche à sa fin, j’espère avoir été clair. Déployer une architecture comme celle-ci (même en virtuelle) m’ a vraiment fait apprendre beaucoup de choses, c’est très formateur. Ici nous n’avons entrevu qu’une petite partie des possibilités de DRBD et Pacemaker mais ce tutoriel reste une base sérieuse pour toute personne voulant débuter avec ces outils. Le prochain article traitera du mode actif/actif. Si vous voulez parfaitement comprendre le fonctionnement de pacemaker et comprendre toutes ses possibilités je vous invite à lire LE guide officiel , qui m’a été très utile.
Comments